
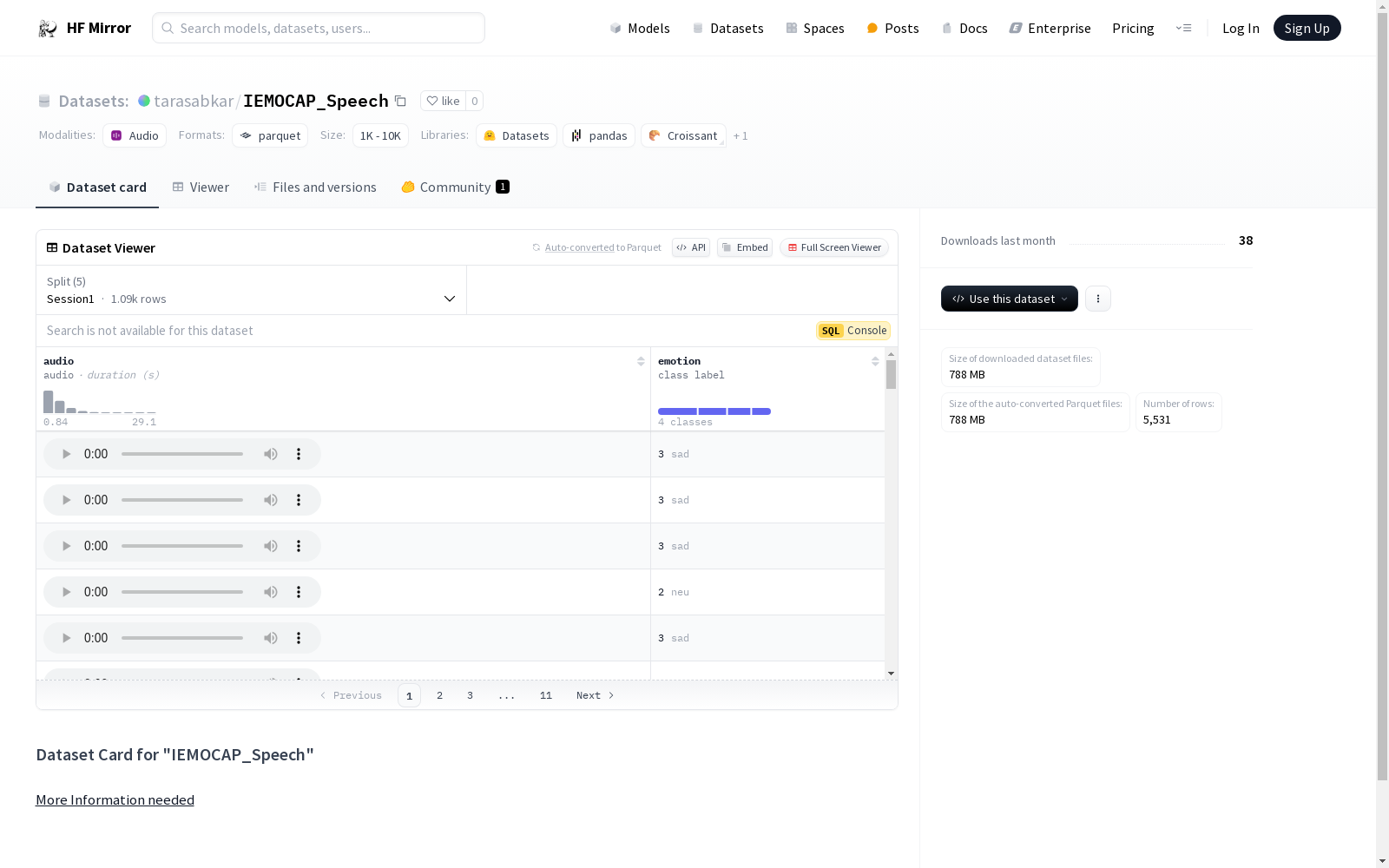
构建方式
IEMOCAP_Speech数据集的构建基于IEMOCAP(InteractiZZZe Emotional Dyadic Motion Capture)数据库,该数据库是一个宽泛用于激情识别钻研的基准数据集。数据集通过聚集和标注多模态数据,出格是音频信号,来捕捉差异激情形态。每个音频样原都颠终精密的激情标注,涵盖了四种根柢激情类别:仇恨(ang)、光荣(hap)、中性(neu)和哀痛(sad)。数据集被分别为五个会话(Session1至Session5),每个会话包孕数百个音频样原,确保了数据的多样性和宽泛性。
特点
IEMOCAP_Speech数据集的次要特点正在于其激情标注的精密性和音频数据的多样性。每个音频样原的激情标签明白,且涵盖了人类激情表达的多个维度,为激情识别算法供给了富厚的训练和测试资料。另外,数据集的音频采样率为16000Hz,确保了音频量质的高范例。五个会话的分别不只删多了数据的多样性,还为跨会话的激情识别钻研供给了可能。
运用办法
IEMOCAP_Speech数据集折用于激情识别和语音办理规模的钻研。钻研者可以操做该数据集训练和评价激情分类模型,摸索差异激情形态下的语音特征。运用时,可以通过HuggingFace的datasets库轻松加载数据集,并依据须要提与音频和激情标签停行模型训练。数据集的构造化设想使得钻研者能够便捷地停行数据收解和模型验证,从而敦促激情计较和语音识别技术的展开。
布景取挑战
布景概述
IEMOCAP_Speech数据集,由tarasabkar发布,专注于激情识别规模,出格是通过语音阐明来识别和分类激情形态。该数据集的焦点钻研问题正在于如何通过语音信号精确捕捉和分类人类的激情,如仇恨、光荣、中性、哀痛等。其创立光阳可逃溯至IEMOCAP项宗旨晚期阶段,次要钻研人员和机构努力于通过多模态交互数据来提升激情识其它精确性和鲁棒性。该数据集对激情计较和语音办理规模具有重要映响力,为钻研人员供给了一个范例化的基准,以评价和比较差异的激情识别算法。
当前挑战
IEMOCAP_Speech数据集正在构建和使用历程中面临多项挑战。首先,激情识其它精确性依赖于对语音信号的精密阐明,那要求算法能够办理复纯的语音特征并区分轻微的激情不同。其次,数据集的构建历程中,如何确保激情标签的精确性和一致性是一个重要挑战,因为激情的表达具有主不雅观性和个别不同。另外,数据集的多样性和代表性也是要害问题,确保涵盖差同性别、年龄和文化布景的语音样原,以进步模型的泛化才华。
罕用场景
规范运用场景
IEMOCAP_Speech数据集正在激情识别规模中具有规范的运用场景,次要用于语音激情分类任务。通偏激析音频数据中的激情特征,钻研人员可以构建模型来识别和分类四种根柢激情:仇恨(ang)、光荣(hap)、中性(neu)和哀痛(sad)。该数据集的高采样率音频数据为激情识别供给了富厚的特征信息,使得模型能够更精确地捕捉语音中的激情厘革。
处置惩罚惩罚学术问题
IEMOCAP_Speech数据集处置惩罚惩罚了语音激情识别中的要害学术问题,出格是正在多激情类别分类和激情强度评价方面。通过供给多样的激情样原和具体的激情标签,该数据集为钻研者供给了一个范例化的基准,用于评价和比较差异激情识别算法的机能。那不只敦促了激情计较规模的展开,还为心理学和语言学等交叉学科供给了重要的钻研工具。
衍生相关工做
基于IEMOCAP_Speech数据集,钻研者们开发了多种激情识别模型和算法,敦促了语音激情识别技术的提高。譬喻,一些钻研工做操做该数据集停行深度进修模型的训练,提出了基于卷积神经网络(CNN)和长短期记忆网络(LSTM)的激情识别办法。另外,该数据集还被用于多模态激情阐明,联结文原和室频数据停行更片面的激情识别钻研。
来了! 中公教育推出AI数智课程,虚拟数字讲师“小鹿”首次亮...
浏览:82 时间:2025-01-13变美指南 | 豆妃灭痘舒缓组合拳,让你过个亮眼的新年!...
浏览:63 时间:2024-11-102022学各国语言的软件哪些好 学各国语言的app推荐...
浏览:28 时间:2024-12-29英特尔StoryTTS:新数据集让文本到语音(TTS)表达更...
浏览:0 时间:2025-02-23PyCharm安装GitHub Copilot(最好用的AI...
浏览:5 时间:2025-02-22JetBrains IDE与GitHub Copilot的绝...
浏览:5 时间:2025-02-22照片生成ai舞蹈软件有哪些?推荐5款可以一键生成跳舞视频的A...
浏览:3 时间:2025-02-22
