
编者按: 跟着正在线集会的普及,用户曾经不再满足于能听到,而是要有更为极致的听感体验,如何能够正在复纯多变的使用场景中照常担保声音明晰流畅是对集会系统的极大挑战。LiZZZexideoStackCon2022上海站大会邀请到了全时 音室频研发部经理 顾骋教师,为各人具体引见了语音前办理技术正在集会场景中的使用取挑战。
文/顾骋
整理/LiZZZexideoStack
各人好,我是顾骋,来自全时,原次分享的主题是语音前办理技术正在集会场景中的使用取挑战。

内容次要蕴含三个方面:第一局部引见映响集会声音量质的因素及应对办法;第二局部引见语音前办理技术正在集会中的使用;第三局部引见语音前办理取深度进修技术的联结及成效。

以下是咱们正在室频集会当中可能常常会逢到的两个场景和问题:
1. 开会时显现纯音,映响参会人员体验
2. 同事讲话时,有他人的键盘声传入映响集会停行
这么,招致孕育发作那些问题的起因是什么呢?
1、如何保障集会中的声音量质


映响声音量质的因素有不少,此中最常见的便是网络。因为声音正在网络传输的历程中会有所丧失,如数据损失、包的乱序,或延时较大招致声音过了好暂才可被听到。针对那个问题,首先咱们须要对相关网络陈列停行保障,其次正在传输层作一些流控,如正在编码时编写冗余信息来反抗丢包问题或是正在解码时依据帧取帧的相关性来预测损失的语音帧。
第二个因素是环境因素,差异于网络因素,环境因素较难察觉。举个例子,同事A正在集会室顶用座机开会时,同事B进入集会室,翻开电脑进入集会,两台方法都开着外放,会招致难听逆耳尖利的啸叫声。或是正在墙面吸音成效较差的房间停行集会时,由于混响较大,较难听清对方声音。另外,随时随地开会的场景很富厚,正在路边开会时,喇叭声传入集会中使得会场凌乱,映响他人体验等等。
第三个是硬件因素。如运用iPhone的场景下回响反映问题显现的概率较小,那是因为它的麦克风扬声器耦折性较好,而局部安卓机由于耦折不良,招致麦克风支罗到的扬声器放出的声音很是大,有的声学设想包孕很多非线性因素。咱们正在安卓机上会专门停行适配调解。用头摘麦的集会成效很抱负,因为它自身是近场拾音,不会支罗到四周纯音,同时不外放的话也就不会显现回响反映。但假如用笔记原电脑开外放,或连贯外置音箱、外置麦克风时,就会显现不少问题。
第四个是软件因素。同一台方法中的同一个软件,正在同样的网络环境中,有时好,有时坏。软件的播放或支罗通过差异线程驱动,当CPU占用高时,录放方法的同步就会显现问题。此时覆信打消模块的近端信号取远端信号之间的时延会发作颤抖,招致回响反映泄露。此外,有不少电脑厂商对声卡作了一些音频办理,如硬件的回响反映打消或噪声克制。然而有些厂商设想的产品未必抱负,招致打消不完全以致语音失实,正在后期运用软件停行算法办理时往往难以去除那局部噪声或回响反映。
2、语音前办理正在集会中的使用
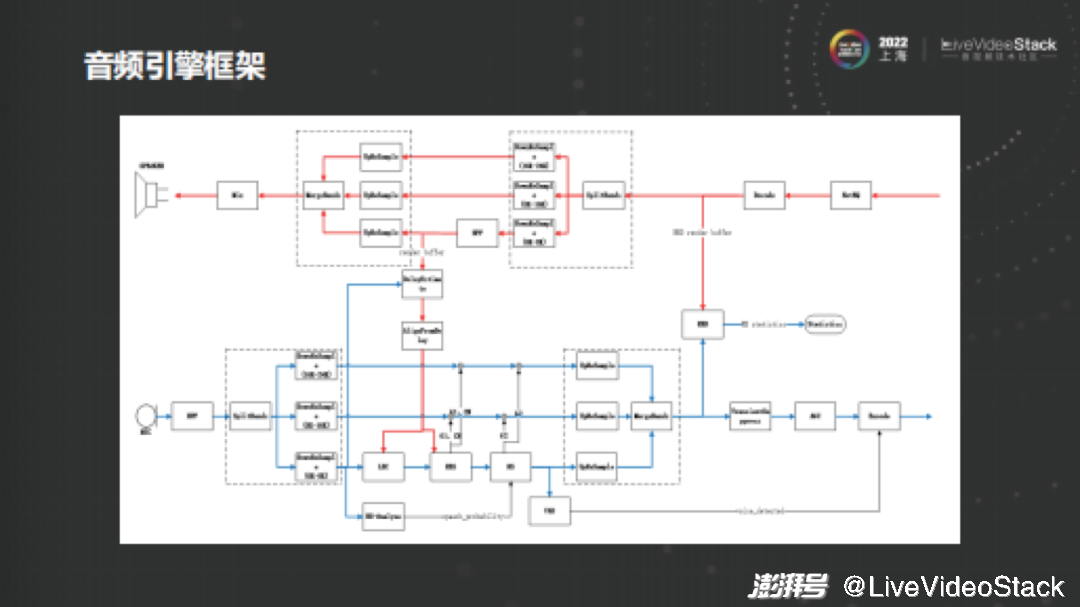
如图所示为音频引擎的大抵流程图。下半局部(蓝线)是uplink链路,麦克风支罗信号后通过高通滤波去除工频烦扰噪声。大局部支罗到的声音是48khz或44.1khz,频次很高,但应付一般语音办理来说频次正在16khz以下便可,所以咱们会先对语音作分频带办理,覆信打消、噪声克制的工做次要正在低频带停行,并将计较出来的删益值映射到高频带,而后再规复成全带信号,最后颠终Agc模块。
Agc可以处置惩罚惩罚由于说话人离麦克风的距离远近厘革招致的声音忽大忽小,以及弥补覆信打消、噪声克制办理历程中对语音组成的誉伤。最末前办理后的音频数据会被编码发送到网络端。
上半局部(红线)是downlink链路,从网络接管的包颠终NetEq办理后解码,与出低频段做为回响反映打消模块的参考信号,同时撑持多通道混音(除语音之外可能会接管到音乐信号,或是局部场景中运用客户端形式混音),最后从扬声器中播放。
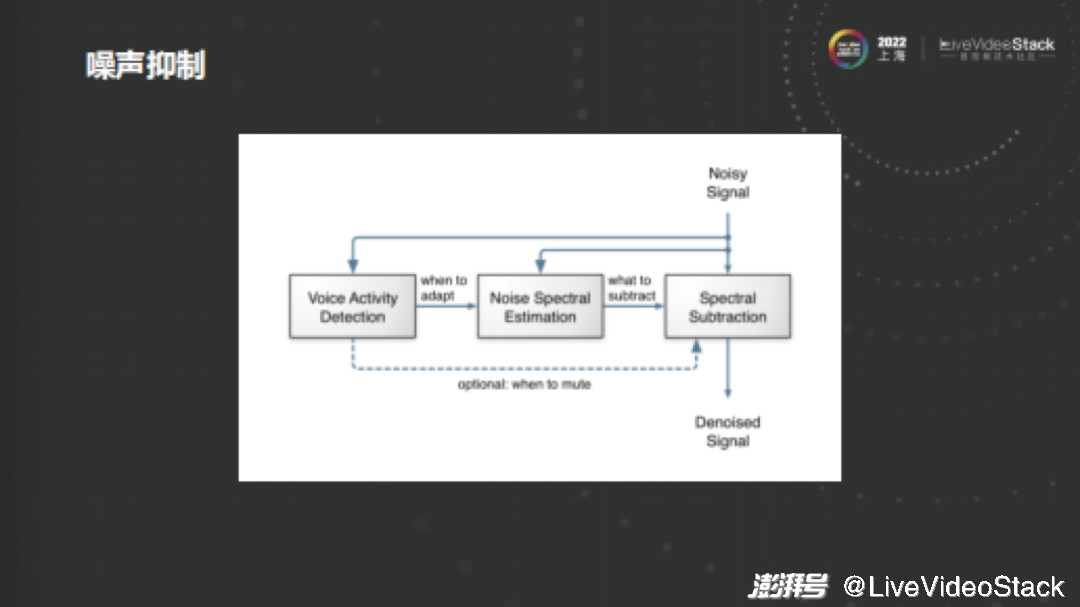
噪声克制和回响反映打消是三个引擎中最重要的两个版块。
如图所示为规范的噪声克制罪能图,传统噪声克制算法首先通过ZZZad检测判断当前是语音还是噪声,而后操做ZZZad检测结果来预算噪声幅度谱,最后从含噪语音幅度谱中减去噪声幅度谱便是杂脏语音的幅度谱,相位信息则是操做了含噪语音的相位谱。

噪声克制分为两步,一步是预计噪声,另一步是计较删益因子。
估噪声最罕用的是MCRA。首先计较大要潦草噪声,操做最小值跟踪法与得噪声的初阶预计。纵然正在语音流动期间也不是所有频点都含有语音,不少频点都会有噪声,因而应付单个频点而言它的幅度谱最末会趋近于噪声的级别。咱们可以通过最小值预计来预算初始噪声级别,再通过光阳递归法对初始噪声停行滑腻办理,假如当前是语音,就用上一帧的数据更新它,假如当前是噪音,就用当前帧的数据更新它。
应付噪声克制来说,咱们可以用简略的谱减法。从含噪的幅度谱中去除噪声幅度谱后便可与得杂脏幅度谱,那无疑是最简略的办法,但弊病很鲜亮,那种办法容易过多去除“噪声谱”,可能会减多,也可能会减少招致音乐噪声的显现。
目前使用较宽泛的办法是维纳滤波,首先操做预算的杂脏幅度谱和抱负幅度谱的均方误差,与其最小值,也便是导数为0的处所,预算出先验信噪比后便可算出维纳滤波系数。虽然也有不少其余办法,如基于统计意义的办法等,且由于人耳对语音的感知是非线性的,咱们可以将幅度谱转换到对数谱,获得的结果会更抱负。
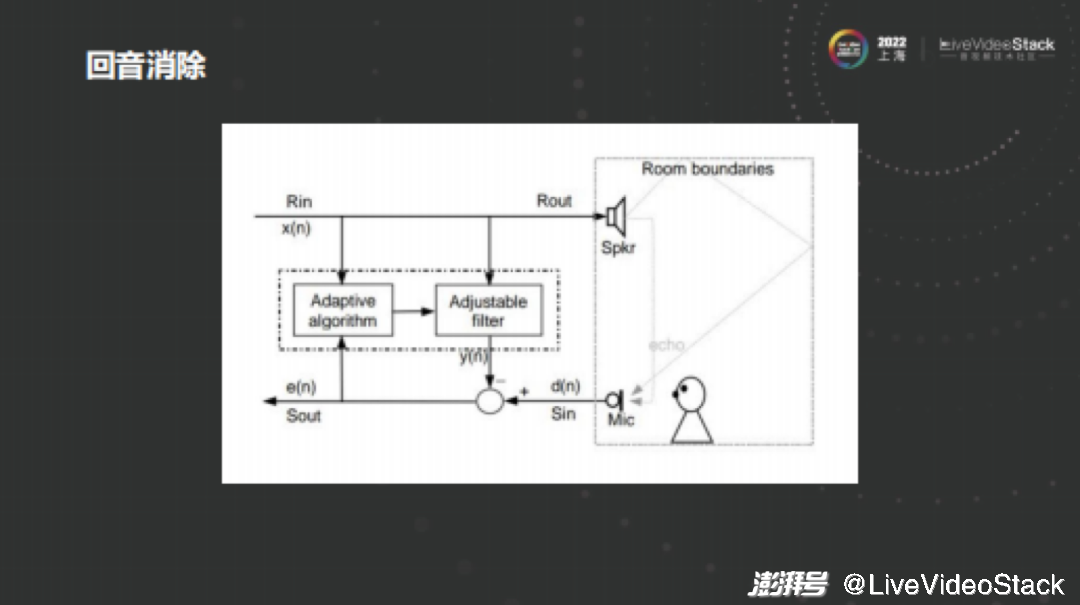
声音从扬声器里播放出来之前,会通过曲达声间接传给麦克风,同时颠终房间的间断反射最末被麦克风支罗,相当于扬声器中传出的声音再次传入麦克风,招致对端说话时能听到原身覆信。针对回响反映,正常作法是通过自适应滤波器预算房间攻击响应,再和远端信号停行卷积,得出预算的覆信信号。真际使用中会更复纯,因为扬声器和麦克风之间有不少非线性耦折,房间也存正在一些混响,而且可能除了远端说话时也有近端正在说话,接续处于双讲形态,招致回响反映打消比较艰难。

应付上文提到的回响反映预计,咱们用到较多的是NLMS自适应滤波器,起因是其有利于工程真现,咱们根柢是通过NLMS方式正在频域分块办理。

回响反映打消次要蕴含以下几多点:
1、时延预计
远端信号首先须要和近端信号对齐。因为正在房间内,扬声器播出的声音会被麦克风支罗,组成时延差,另外,声卡的输入和输出存正在缓存buffer,再加上支罗播放线程差异步等问题,不成防行地会引入时延。时延较小时,由于线性滤波器自身有一定长度,能够对消时延,所以问题不大,但其时延较大时就须要给取时延预计较法,比如用最简略的相互关法。
2、线性回响反映打消
给取自适应滤波器能够预算出回响反映正在房间内的流传途径,获得线性回响反映预计。此中归一化最小均方误差(NLMS)使用最为宽泛,咱们往往通过控制迭代步长来使其尽快支敛,抵达不乱形态。
3、双讲检测
这么如何加速支敛速度呢?那就须要双讲检测算法(dtd),因为正在仅有远端说话时应尽快更新滤波器,但假宛如时有近端说话时,应尽质冻结滤波器以防发散。其真双讲检测收配起来比较艰难,因为正在有噪声烦扰时检测很难精确。正在不少场景咱们选择通过控制迭代步长起到类似双讲检测做用,同时为了进步支敛速度,咱们给滤波器组的每个块分配差异权重,比如更近的块权重更大,从而支敛更多。
4、残留回响反映克制
正在真际场景中,线性回响反映蕴含很是大的非线性成分,简略地通过线性滤波器无奈彻底打消,所以须要通过RES预算残留回响反映并克制。正在控制历程中会发现,克制力渡过小时,回响反映打消的不干脏,但假如力渡过大则会誉伤语音,那也是真际使用中最具有挑战性的。
3、拥抱深度进修逃求极致音量

宛如上文所提到的,咱们基于传统数字信号办理方式停行语音前办理,如打消回响反映,打消噪声。
传统的降噪根柢基于先验的如果条件如如果是一个加性噪声,它和语音不相关,还得是颠簸的。应付颠簸噪声的办理没有太大问题,但应付某些场景如鼠标键盘敲击声,办理起来的成效会不太抱负。假如用传统办法提与鼠标键盘声的特征停行克制,难点正在于兴许诺以正在个体场景下通过不雅察看频谱分布提与有效特征,但由于噪声类型厘革太多,招致正在其余场景下,特征提与不准,另外人工调参工做质也是非常弘大。
那就表示出深度进修的劣势,它供给了很是壮大的非线性拟折才华,纵然是百万级的参数质,只有有足够好的数据,通过训练后便可抵达较好成效。

正常咱们会先选定模型,设置训练目的如计较一个mask,那个mask相当于传统算法中的gain值,最初比较简略的是抱负二值掩膜,判断频点是语音或噪音,那往往会引入一些噪声。厥后咱们通过抱负比值掩膜计较比值而不是简略的作一个二分类。

后续引入了不少相位信息,发现相位对音量有较大映响。最后咱们选择了cIRM,它同时思考了幅度和相位,抵达更好的成效。虽然正在真际运用中还是须要联结详细场景停行选择。

训练网络须要有很是壮大的泛化才华,否则正在某些场景下的成效会不太抱负,于是咱们须要对样原停行删广,应付目前已有的训练数据集停行一些办理或依据须要使用的场景运用私有的训练数据。同时还需找到较适宜的特征。假如通过映射方式间接输入时域波形,这么最后间接输出的便是曾经完成降噪的时域波形,但那会提升训练难度。所以咱们正常会适当提与一些特征,比如将其转换到一个频域或通偏激带的方式切割为多个带。更多或更适宜的特征提与能够有效降低模型的大小。

之所以那样作,是因为真际的使用场景根柢都是真时的。可能各人看到很多挑战赛中的成效很是抱负,但假如间接拿来陈列就会发现根基无奈运止,因为假设10ms一帧的数据,须要运算50ms威力出结果,那根基达不到真时性的要求,换句话说,正在好的呆板上能跑起来,但换到较差的呆板就不止了。所以最末的抉择还应综折真际使用场景、呆板机能,及陈列正在端侧还是效劳器。陈列正在效劳器上可以通过较好的gpu提升机能。挪动端和pc、mac实个办理上也存正在一些不同。嵌入式方法还应思考存储质的问题,假如参数质过大会对其存储组成一定映响。
咱们依据使用场景选择适宜的模型后,还会不停的停行劣化,或对数据作一些办理,再加上陈列,那样才华够担保明时性。
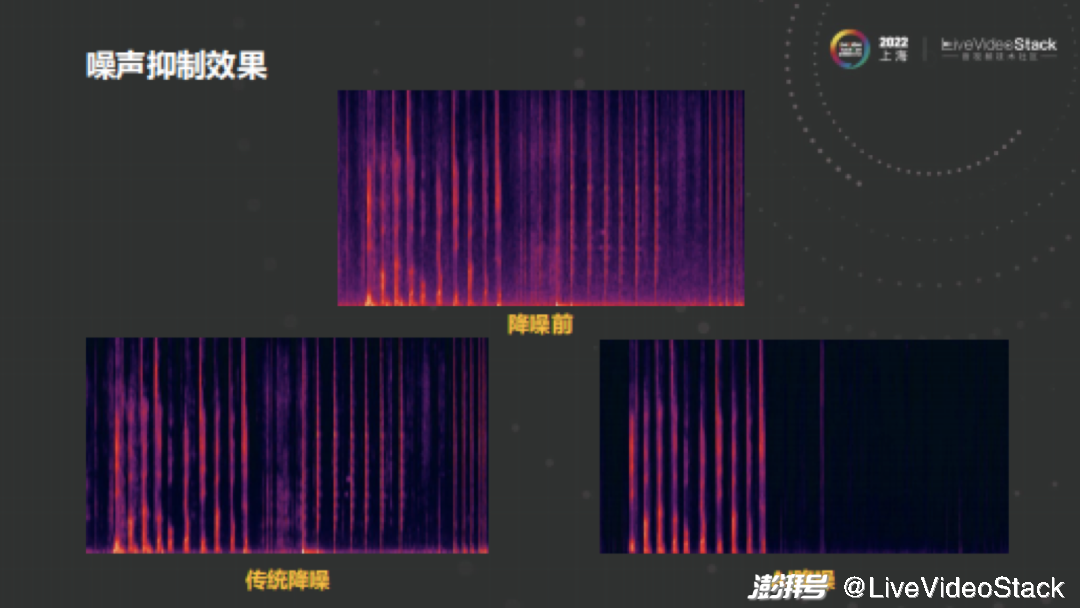
举个例子,噪声里面的瞬态噪声对传统降噪来说很难办理,如图中传统降噪前后的对照,此中的颠簸噪声根柢能够被打消,但鼠标键盘那种噪声就无奈彻底打消了。而AI降噪方式能够较好地办理那种状况。
回响反映打消也类似,其切真回响反映打消中存正在一个大问题,即打消回响反映算法逢到双讲状况时会对原地语音组成很大誉伤,通过AI算法停行较好的训练后能够很好的处置惩罚惩罚那个问题。

各人可能感觉目前基于深度进修的办法曾经可以代替传统办法了,但真际上却没这么简略。深度进修的办法当然好,能够处置惩罚惩罚很多传统方式处置惩罚惩罚起来比较艰难的问题,但它也其真不是全能的。使用基于深度进修的办法时,假设数据集笼罩很片面,成效兴许会很不错,但当数据集和真正在场景存正在一定不同时,最末成效也会大打合扣。
此外一个重要问题是机能,由于咱们的计较资源往往比较有限,而深度进修办法的机能开销却很大,应付真时性要求很高的场景来说,方法机能不够,深度进修的办法未必是最好的选择。目前大多还是深度进修加传统相联结的方式,相当于与精髓去糟粕,用传统方式完成最根原罪能,把复纯的局部交给深度进修,正在保障机能的前提下尽可能进步运用成效。

最后,咱们来总结下:
1、一场集会有很多构成局部,但声音往往是最为重要的。一方面不是所有人都喜爱开着室频,另一方面声音的卡顿会比室频的卡顿更令人抓狂,一帧声音数据的损失就会被人鲜亮的感知到。
2、映响声音的因素有不少,蕴含环境、硬件、软件等因素,都会带来差异的体验。
3、针对那些问题,可以操做语音前办理技术停行噪声克制以及回响反映的打消。
4、深度进修和传统办法工力悉敌,之间的劣势可以互补。
“挤进”黛妃婚姻、成为英国新王后的卡米拉,坐拥多少珠宝?...
浏览:59 时间:2024-08-08变美指南 | 豆妃灭痘舒缓组合拳,让你过个亮眼的新年!...
浏览:56 时间:2024-11-10人工智能在时尚设计中的应用,如何利用AI为服装线稿填充面料...
浏览:3 时间:2025-01-25服装设计的AI绘画表达探索:以Midjourney文生图工具...
浏览:3 时间:2025-01-25
